
通販・D2C・Eコマース事業者の
EC物流代行・発送代行・オムニチャネルコマースでの流通加工から店舗物流までを、一般社団法人 通販エキスパート協会認定スペシャリスト:「通販CXマネジメント」・「フルフィルメントCX」メンバーとスタッフがサポート致します。
全国11拠点のDC/FCから、先進RaaSマテハンロボット・RFIDなどと、OMS・WMSとコマースシステムをAPIで連携して、物流・発送代行サービスを「スタートアップ特別限定プラン」から、100億円を超える事業者に最適な分散保管・分散出荷、返品・交換サービスまでを一貫でデザインする「顧客購買後体験」によって、LTVの向上が実現できる「感動物流サービス」を提供中です。物流業界の最新トレンドを盛り込んだお役立ち資料も無料でご提供しています。

データ サイエンスは、IT 業界で最も急速に成長しているサブセクターの 1 つです、ビジネス運営に不可欠な要素となってきています。
ヘルスケア セクター、金融セクターに注目されがちですが、実は、 Amazon のようなオンライン小売業者でこそ、通常、データの収集と分析は、それぞれの新しい市場分野の将来を予測する上で重要な役割を果たしています。
ビッグデータ分析、データ サイエンス、人工知能のイノベーションは、世界中の組織の管理方法を変えており、2023 年のデータ サイエンス トレンドのトップ 10 に入っています。
誰が競争に勝ったかを知る必要がある場合、データが差別化要因になります。そして、データが現代の新しい「金」であるためです。
人工知能 Artificial Intelligence
人工知能は、将来の生活、仕事、ビジネスの方法に影響を与える可能性が最も高い技術開発です。それを使用することで、ビジネス分析はより正確な予測を行い、データの収集やクリーニングなどの骨の折れるプロセスに費やす時間を短縮し、スタッフがポジションや技術的専門知識のレベルに関係なく、データ主導の洞察に基づいて行動できるようにします。
テクノロジーの巨人は、社名を「メタ」に変更してから約1年半後、人工知能の進歩が投資の最優先事項になると述べ、将来のインターネットバージョンである「メタバース」の構築にコミットします。
CEO のMark Zuckerberg は、プロジェクトの合理化と経費の削減に集中しています。
メタバースの構築は「社会的つながりの未来を定義する上で依然として中心的である」としていますが、メタバースはその資金のほとんどをそこに費やすことはない. Meta の目標は、AI を改善することです。
ザッカーバーグは
「私たちの最大の投資は、AIを進歩させ、それを私たちのすべての製品に組み込むことです」と述べました。
シミュレートされたインテリジェンス デバイスが、そのアプリケーションのクライアントが自分の考えを伝え、「新しい幸せを見つける」のにどのように役立つかを身振りで示しました。より良いコードをより速く。」
マイクロソフトが支援する OpenAI が 11 月末に ChatGPT を公開したことをきっかけに、テクノロジーの世界で AI 熱狂が高まっています。Meta とその前身である Facebook は何年にもわたって AI 研究に携わってきましたが、ユーザーのプロンプトに対して説得力のある人間のような応答を生成する能力があるため、この技術は急速に普及し、テクノロジー企業間の明らかな AI 軍拡競争に火をつけました。
2 月初め、Microsoft は、ChatGPT の背後にある技術が検索エンジンの Bing に組み込まれることを発表しました。Google は、Microsoft よりも 1 日早く、AI を活用したツールである Bard を発表しました。
さらに、Meta は同社の AI ツール開発の取り組みを「ターボチャージ」するために「トップレベルの製品グループ」を設立すると発表しました。
Meta の AI への投資は、製品エンジニアをより効率的にすることができ、AI 機能を Meta のアプリ ラインナップに組み込むことで、ユーザーがより多くの時間を費やすようになり、広告収入の増加につながる可能性があるため、「両端にメリットがあります」
「AI への多くの投資と、AI への投資から得られる多くの機能強化は、メタバース プロジェクト全体に適用できます」
データの民主化 Data Democratisation
選択したビジネスの可能性だけでなく、組織内に経験豊富なデータ サイエンティストが不足しているために失われる可能性があるものにも対処するために、ビジネスにとってデータ アクセスをシンプル、迅速、かつ信頼性の高いものにすることが目的です。
データの民主化とは、組織内のあらゆる人が必要なデータにアクセスし、データを自由に操作して活用できる状態を指します。このような状態になることで、意思決定のスピードや精度が向上し、より効率的なビジネスの実現が可能となります。
データの民主化を導入する際のポイントは以下の通りです。
-
データのアクセス権限を明確にする
データの民主化を実現するためには、組織内でデータにアクセスできる人を明確にする必要があります。データの機密性や安全性を考慮しながら、必要な情報にアクセスできる人を限定することが重要です。
-
データの可視化を行う
データの可視化は、データを理解するために欠かせない要素です。グラフやチャートなどの視覚的な手段を使ってデータを表現することで、複雑なデータをわかりやすく伝えることができます。
-
データの分析能力を向上させる
データの民主化を実現するには、組織内でデータ分析のスキルを向上させることも重要です。組織内でデータに精通した人材を育成し、データ分析を行うためのツールやプラットフォームを提供することで、組織全体でデータを活用できる環境を作り出すことができます
-
データの共有を促進する
データの民主化を実現するためには、組織内でデータの共有を促進することが重要です。データを共有することで、異なる部署やチームで得られた情報を組み合わせることができ、より正確な意思決定ができるようになります。
-
クラウドサービスの活用
データの民主化を実現するためには、クラウドサービスを活用することも有効です。クラウドサービスを利用することで、データをオンライン上で共有したり、必要なときに必要なデータにアクセスしたりすることが容易になります。
データの民主化を導入する際のポイントは、以下の通りです。
-
データ品質の向上を図る
データの品質が低い場合、意思決定の際に誤った判断をする可能性があります。そのため、データ品質を向上するための取り組みを行うことが重要です。データ品質を向上させるためには、データの入力方法や管理方法を見直し、正確性や信頼性を高めることが必要です
-
データの標準化を行う
組織内で使用されるデータが標準化されていない場合、異なる部署やチームでデータを共有したり分析したりする際に問題が生じる可能性があります。そのため、データの標準化を行うことで、データの整合性や品質を向上させることができます
-
データのセキュリティを確保する
データの民主化を実現するためには、データのセキュリティを確保することが重要です。データへの不正アクセスや漏洩を防ぐために、適切なセキュリティ対策を導入することが必要です
-
データに基づく意思決定を促進する
データの民主化を実現することで、組織内でデータに基づく意思決定が促進されます。データを活用することで、より正確で客観的な意思決定が可能となり、業務の効率化や経営戦略の立案につながります
-
データの文化を醸成する
データの民主化を実現するためには、組織内でデータの重要性を認識し、データを活用する文化を醸成することが必要です。データに対する理解や知識を共有し、データを活用することが当たり前の状態を作り出すことが重要です
以上が、データの民主化を導入する際のポイントです。これらの取り組みを行うことで、組織全体でデータを活用する文化を醸成し、ビジネスの効率化や競争力の強化につながることが期待されます。
自動 ML Auto-ML
自動化された機械学習は、データ分析における最新の進歩です、すぐになくなることはないようです。データ サイエンスの民主化は現在、自動化された機械学習によって推進されています。自動機械学習により、以前は肉体労働が必要だった労働集約的で反復的なタスクの効率が向上します。自動 ML のおかげで、データ サイエンティストは、データの準備や精製などの時間のかかるタスクを気にする必要がなくなりました。
Auto-MLとは、自動機械学習(Automatic Machine Learning)の略称で、機械学習モデルの開発プロセスを自動化する技術です。Auto-MLを導入することで、機械学習の専門知識がなくても、簡単に高度な予測モデルを構築できるようになります。
Auto-MLを導入する際のポイントは、以下の通りです。
-
導入する目的を明確にす
Auto-MLを導入する目的を明確にすることが重要です。具体的にどのような問題を解決するために導入するのか、どのようなデータを使用するのかを定め、導入前に目的を明確化することが必要です。
-
使用するデータを整備する
Auto-MLを使用するにあたり、使用するデータを整備することが重要です。データの前処理や欠損値の処理など、機械学習に適した形式に変換することが必要です
-
Auto-MLのツールの選定
Auto-MLには、様々なツールがあります。自社のニーズに合ったツールを選定することが重要です。ツールの性能や機能、利用料金、サポート体制などを比較検討し、自社のニーズに合ったツールを選択することが必要です。
-
設計・運用フェーズのスキルアップ
Auto-MLを導入する場合、設計・運用フェーズでのスキルアップが必要です。Auto-MLは自動化されているものの、専門的な知識やスキルが必要となります。Auto-MLを運用する担当者に対して、適切なトレーニングや研修を行うことが必要です。
-
自動化されたモデルの精度検証
Auto-MLによって自動生成されたモデルの精度を確認することが必要です。自動化されたモデルには、必ずしも最適なモデルが生成されるとは限りません。そのため、自動化されたモデルの精度を確認し、必要に応じてモデルの修正を行うことが必要です。
-
セキュリティ対策の実施
Auto-MLを導入する際は、データセキュリティに対する対策をしっかりと実施することが重要です。Auto-MLで使用するデータは、企業の機密情報を含むことがあるため、アクセス制限やデータの暗号化、セキュリティポリシーの策定など、セキュリティ面に対する対策を実施することが必要です。
-
継続的な監視と改善
Auto-MLを導入した後は、継続的な監視と改善が必要です。モデルの精度や性能を定期的に監視し、必要に応じて改善を行うことで、より高度な予測モデルを構築することができます。また、Auto-MLを導入することで、新しいデータに対応するために、モデルを継続的に改善することができます。
以上が、Auto-MLを導入する際のポイントです。Auto-MLは、機械学習の専門知識がなくても簡単に高度な予測モデルを構築できるというメリットがありますが、適切な準備や設計・運用フェーズでのスキルアップ、セキュリティ対策の実施など、十分な対策を実施することが重要です。
NLP (自然言語処理)(Natural Language Processing)
NLP は、人工知能、言語学、およびコンピューター サイエンスの多くのサブフィールドの 1 つです。利用可能な処理性能と大量のデータを必要とするため、近年人気が高まっています。
NLP (自然言語処理) は、人工知能の一分野で、自然言語を解析し、理解、生成することを目的とした技術です。NLPは、機械翻訳、文章生成、感情分析、音声認識、自動要約などのアプリケーション分野で応用されています。
NLPを導入する際のポイントは以下の通りです。
-
目的を明確にする
NLPを導入する前に、どのような目的で使用するのかを明確にすることが重要です。例えば、顧客からのフィードバックを自動的に分類するシステムを構築する、大量の文章から特定の情報を収集する、などの目的が考えられます。目的によって必要な技術やアプローチが異なるため、まずは目的を明確にすることが必要です。
-
データの収集と前処理
NLPに必要なデータを収集し、前処理を行うことが重要です。例えば、自然言語で書かれた文章を収集する場合、テキストデータの収集やクレンジング、形態素解析などを行う必要があります。また、データの品質を高めるために、スペルチェックや文法チェックを行うことも重要です。
-
モデルの選定
NLPでは、様々なモデルが存在しています。例えば、機械学習を用いた手法や、ルールベースの手法などがあります。目的やデータの性質に応じて適切なモデルを選定する必要があります
-
モデルの学習とチューニング
選定したモデルを用いて、学習を行います。学習には、大量のデータと計算リソースが必要となります。また、学習の結果に応じて、ハイパーパラメータのチューニングなどが必要になる場合もあります。
-
モデルの評価と改善
モデルの評価を行い、精度や性能を評価します。不十分な場合は、モデルの改善を行う必要があります。また、新しいデータが入ってきた場合にも、モデルを改善する必要があります。
-
セキュリティ対策の実施
NLPで扱うデータには、個人情報や機密情報などの重要な情報が含まれる場合があります。そのため、NLPシステムのセキュリティ対策を実施することが重要です。例えば、データの暗号化やアクセス制御などを行うことで、情報漏洩のリスクを低減することができます。
-
ユーザビリティの向上
NLPシステムを導入する場合、ユーザビリティを考慮することが重要です。ユーザがシステムを使いやすいように、インタフェースの設計やドキュメンテーションなどを工夫する必要があります。
-
継続的な保守・運用
NLPシステムは、データの変化や技術の進歩に追随する必要があります。そのため、継続的な保守・運用が必要です。新しいデータの収集やモデルの更新、不具合の修正などを行い、システムを維持・改善する必要があります。
以上が、NLPを導入する際のポイントです。NLPは、自然言語を解析し、自動化を実現することができるため、様々な分野で応用が期待されています。しかし、導入にあたっては、上記のポイントを抑えることが重要です。
データ規制とガバナンス Data Regulation and Governance
データ ガバナンスは、データ処理、分析、研究のすべての側面、つまり、人間と人間以外のデータとの相互作用にとって重要です。GDPR などのデータ セキュリティおよびプライバシー規則を順守しながら、組織全体で安全なデータ交換のためのプラットフォームを提供することは、高品質で監視されたデータを保証するプロセスです。
データ規制とガバナンスは、データの収集、使用、共有、保存などに関するルールや規制のことを指します。これらは、個人情報保護、データセキュリティ、データ品質、データアクセシビリティなどの問題を解決するために重要な役割を果たします。
データ規制は、法律や規則によって定められたルールであり、データ収集、使用、共有、保存などのプロセスにおいて、どのようなデータをどのように扱うことができるかを明確に定めるものです。個人情報保護法やGDPR(EU一般データ保護規則)などが代表的なデータ規制の例です。
一方、データガバナンスは、データに対する責任と権限を明確に定めることによって、データの品質、セキュリティ、アクセシビリティを確保するための枠組みです。具体的には、データ管理の責任者を設置し、データの収集、使用、共有、保存などのプロセスを適切に管理することが含まれます。データガバナンスには、データ品質の向上やコンプライアンスの確保などの効果が期待できます。
データ規制とガバナンスは、企業にとって重要な課題です。データの取り扱いに関する法的な要件を満たすことは、企業の信頼性や法的なリスク管理につながります。また、データガバナンスを実施することによって、データ品質の向上やセキュリティの強化、効率的なデータ利用が可能になります。
データ規制とガバナンスを実施するには、以下のようなポイントが重要です。
-
データの分類
データの分類によって、取り扱い方が異なることがあります。例えば、個人情報や機密情報などは、特に厳格な取り扱いが必要です。そのため、データの分類を行い、取り扱い方のルールを設定することが重要です。
-
データ管理の責任者の設置
データの取り扱いを責任者に任せることで、データ管理の一元化を図り、データの取り扱いを一貫性のある方法で行うことができます。データ管理の責任者は、データガバナンスにおいて重要な役割を果たします。
-
ポリシーの策定
データの取り扱いに関するポリシーを策定し、社員に周知徹底することが重要です。ポリシーには、データの収集、使用、共有、保存などに関するルールが含まれます。また、ポリシーに基づくコンプライアンスチェックを定期的に実施することも大切です。
-
セキュリティ対策の実施
データの取り扱いに関するセキュリティ対策を実施することが重要です。例えば、データの暗号化やアクセス制御などを実施することで、データのセキュリティを強化することができます。
-
監査の実施
データの取り扱いに関する監査を定期的に実施することで、データガバナンスの適切な実施を確認することができます。監査結果に基づき、必要に応じて改善策を講じることが大切です。
-
教育・トレーニング
データの取り扱いに関する教育・トレーニングを実施することで、社員の意識向上やスキルアップを図ることができます。データガバナンスに関する教育・トレーニングを行うことで、データの適切な取り扱いができるようになります。
以上が、データ規制とガバナンスを実施するためのポイントです。データ規制とガバナンスは、企業の信頼性向上や法的リスク管理につながる重要な課題であるため、適切な対策を講じることが求められます。
サービスとしてのデータ Data-as-a-Service
ヘルスケア業界の DaaS (Data-as-a-Service) ビジネスは、COVID-19 パンデミックが最初に表面化して以来、機会が増えています。より多くの顧客が高速インターネットにアクセスできるようになるにつれて、DaaS の使用は拡大すると予測されています。
Data-as-a-Service(DaaS)は、データをサービスとして提供するビジネスモデルであり、顧客が必要なデータにアクセスできるようにします。顧客は、自社でデータを収集・処理する必要がなく、必要なデータを購入することができます。
DaaSは、企業にとって以下のようなメリットがあります。
-
コスト削減
データの収集・処理にかかるコストを削減できます。自社でデータを収集するために必要な機器や人員を抑えられるため、コスト削減につながります。
-
リアルタイム性の向上
DaaSを利用することで、必要なデータにリアルタイムでアクセスできるため、ビジネスプロセスのスピードアップにつながります。
-
データの品質向上
DaaS提供者は、データ品質を維持するための一定の品質管理を行っています。そのため、データの品質が向上し、正確な分析が可能になります。
-
規制対応の簡素化
DaaS提供者は、データの取り扱いに関する規制に対応するための対策を講じています。そのため、顧客は、規制対応のために膨大な労力を割く必要がなくなります。
DaaSを導入する際のポイントとしては、以下のことが挙げられます。
- 提供されるデータの種類や品質についての確認DaaS提供者が提供するデータの種類や品質について、事前に確認することが重要です。必要なデータが提供されているか、正確なデータであるかを確認することが大切です。
-
セキュリティの確保
DaaS提供者が提供するデータは、クラウド上で保管されていることが多いため、セキュリティについて十分な確認が必要です。データの保護やアクセス制御が十分に実施されているかを確認することが大切です。
-
サービスレベル契約 (SLA) の確認
DaaS提供者とのサービスレベル契約 (SLA) を締結し、サービスレベルや利用料金、データの使用期間などについて明確にすることが重要です。また、データ提供者の変更や、データの削除・追加についても、SLAに明確に規定されていることを確認することが重要です。
-
利用目的の明確化
DaaSを利用する目的や、取得したデータをどのように利用するのかを明確にすることが必要です。利用目的がはっきりとしていないと、データ提供者との契約違反になる可能性があるため、事前に確認しておくことが重要です。
-
データの利用に関する規制の確認
DaaSを利用する場合には、データ利用に関する規制を確認することが必要です。例えば、個人情報保護法や知的財産法などに違反する可能性がある場合は、利用できない場合があります
以上のように、DaaSを導入する際には、データの品質やセキュリティ、利用料金などを十分に検討し、契約書を確認することが重要です。また、利用目的や規制に関する確認も欠かせません。
データ ファブリック Data Fabric
データ ファブリックは、さまざまなエンドポイントと複数のクラウドにわたってエンド ツー エンドの機能を提供するアーキテクチャとサービスのグループに付けられた名前です。これは堅実なアーキテクチャであるため、さまざまなオンプレミス クラウドおよびエッジ デバイスに展開できる共通のデータ管理戦略と実用性を提供します。
データファブリック(Data Fabric)は、データの集積や処理、分析を統合的に行うための枠組みです。複数のデータソースからのデータを統合し、様々な場所からアクセス可能な形で提供することができます。
データファブリックは、データの集積・統合・融合を行うことで、企業内に散在するデータの価値を最大化することができます。また、データの品質やセキュリティに配慮した上で、データの共有を実現することができます。
具体的には、データファブリックは以下のような機能を提供します。
-
データの統合
データファブリックは、複数のデータソースからデータを収集・統合し、一元化したデータを提供することができます。これにより、データの重複や食い違いを避け、データの品質を向上させることができます。
-
データの共有
データファブリックは、複数のユーザーがデータにアクセスできるようにすることができます。データセキュリティに配慮し、アクセス権限を管理することができます。
-
データの分析
データファブリックは、分散されたデータを効率的に分析することができます。また、分析結果をリアルタイムに反映することができるため、ビジネスの意思決定に活用することができます。
-
データの保管
データファブリックは、データをクラウド上に保管することができます。クラウド上に保管することで、データの可用性や災害対策などを高めることができます
-
データの移行
データファブリックは、複数のデータソースからデータを収集し、新しいシステムへの移行をスムーズに行うことができます。
データファブリックを導入することで、企業内に散在するデータを統合的に活用することができます。また、データセキュリティやアクセス権限管理などの問題も解決することができます。
データファブリックを導入するにあたっては、以下のようなポイントに注意する必要があります。
-
データ品質の向上
データファブリックは、複数のデータソースからデータを収集・統合することができますが、その際にデータ品質が低下することがあります。データの重複や食い違いを避け、データ品質を向上するための取り組みが必要です。
-
セキュリティ対策の強化
データファブリックは、複数のユーザーがデータにアクセスできるようにするため、セキュリティ対策が重要です。アクセス権限の管理やデータ暗号化など、セキュリティ対策を徹底することが必要です。
-
データの利活用方法の検討
データファブリックを導入することで、データを効率的に統合・分析することができます。しかし、データの利活用方法を明確にすることが重要です。データの利用目的や分析方法を検討し、ビジネス価値を最大化するための取り組みが必要です。
-
IT基盤の整備
データファブリックを導入するには、クラウド基盤の整備が必要です。クラウドサービスを利用する場合には、クラウドベンダーとの契約やサービスレベルアグリーメント(SLA)の確認などが必要です。
- データガバナンスの確立
データファブリックを導入することで、多くのデータが一元化されます。そのため、データガバナンスを確立することが必要です。データの所有者や利用者、データの更新頻度などを明確にすることで、データの適切な管理を行うことができます。
以上のように、データファブリックを導入する際には、データ品質の向上やセキュリティ対策の強化、データの利活用方法の検討など、様々なポイントに注意する必要があります。
ロボティック プロセス オートメーション (RPA) Robotic Process Automation
RPA は、退屈で反復的なプロセスを完璧に、迅速に、一貫して自動化するため、2023 年には最先端のソフトウェア テクノロジになるでしょう。
ロボティックプロセスオートメーション(RPA)は、人間が行っていたルーチン業務をソフトウェアロボットに自動化する技術です。以下では、RPAの概要と導入ポイントについて説明します。
【RPAの概要】
RPAは、業務の自動化によって生産性を向上し、人的ミスを減らすことができます。ルーチン業務に限定した自動化であるため、実装が容易であり、導入コストも比較的低く抑えることができます。
【RPAのポイント】
-
ルーチン業務の把握
RPAを導入する前に、どのような業務がルーチン業務であるかを把握する必要があります。人手で行うことが多いデータ入力や集計、ファイルの保存や転送など、繰り返し行う作業が対象となります。
-
プロセスの標準化
RPAは、ある一定の作業手順を自動化するため、作業手順を標準化することが必要です。業務フローの定義やマニュアルの整備、作業手順の改善などを行い、プロセスを明確にすることが重要です。
-
システムの連携
RPAが必要とするデータや情報を取得するためには、システム間の連携が必要です。システムのAPIやWebサービス、データベースなどにアクセスするための設定を行うことが必要です。
-
セキュリティ対策の強化
RPAは、重要な業務を自動化するため、セキュリティ対策が重要です。アクセス制御の強化、データの暗号化、ログの管理などを徹底することが必要です。
-
管理体制の整備
RPAを導入する場合、ソフトウェアロボットの運用管理やトラブルシューティング、バージョン管理などを行うための管理体制の整備が必要です。
以上のように、RPAを導入する際には、ルーチン業務の把握やプロセスの標準化、システムの連携やセキュリティ対策の強化、管理体制の整
RPAの導入ポイントについては以下の通りです。
- ルーティン業務の自動化:RPAは、繰り返し行われるルーティン業務を自動化するのに適しています。例えば、データ入力、請求書処理、在庫管理、人事業務などが挙げられます。
- 既存システムとの統合:RPAは既存のシステムと容易に統合できます。そのため、既存システムの業務プロセスをよりスムーズかつ効率的にすることができます。
- 高い精度と速度:RPAは、高い精度と速度で業務を処理できます。そのため、精度が重要な業務や、時間が重要な業務などに導入されることが多いです。
- マニュアルタスクの削減:RPAは、マニュアルタスクを削減することができます。そのため、人的ミスやタスクの遅れを防ぎ、人的リソースを他の業務に充てることができます。
- 規模の拡大:業務の規模が大きくなるにつれ、RPAを導入することで、効率的かつ正確に業務を処理することができます。そのため、業務の規模が拡大する企業や組織にとっては、導入が有効です。
以上が、RPAの導入ポイントです。ただし、RPAを導入する際には、事前に十分な検討と計画が必要です。また、RPAはあくまでも人間の代替手段として導入されるべきであり、業務プロセスの改善とともに導入することが望ましいです。
フェデレーテッドラーニングFederated learning
Federated learningでは、エッジ デバイス (携帯電話など) またはサーバーを使用して、機械学習技術を使用して分散データにアクセスします。初期データが中央サーバーに送信されることはありません。ツールに取り付けられたままです。他の誰もデータにアクセスできないため、この手法にはデータのセキュリティとプライバシーの利点があります。アルゴリズムのローカライズされたバージョンは、ローカル データでトレーニングされます。その後、学習出力を中央サーバーと共有して、「グローバル」モデルまたはアルゴリズムを生成できます。その後、学習を続けるために、エッジ デバイスはデータを再共有できます。
Federated learning(フェデレーテッドラーニング)とは、機械学習における新しい手法の一つで、複数の端末に分散して保持されているデータを、中央集権的なサーバーに集めずに、ローカルで学習を行い、その結果を共有して学習モデルを改善していく方法です。
具体的には、クラウドサーバーにデータを集約せず、個々の端末に学習モデルをダウンロードしてローカルで学習を行います。学習が完了した後に、端末から収集されたパラメーターのみが中央集権的なサーバーに送信され、学習モデルの改善に役立てられます。このように、個人情報や機密情報を中央集権的なサーバーに送信することなく、データ保護を維持しながら、分散したデータを利用した学習モデルの改善が可能になります。
Federated learningのメリットとしては、以下のようなものがあります。
- プライバシーの保護:データを中央集権的なサーバーに集めず、ローカルで学習を行うため、個人情報や機密情報を保護することができます。
- 学習モデルの改善:複数の端末に分散したデータを利用することで、より幅広いデータに対応した学習モデルを改善することができます
- コスト削減:クラウドサーバーにデータを集約する必要がないため、クラウドストレージや通信コストを削減することができます。
Federated learningは、特にIoTデバイスやスマートフォンなどの端末において、大量のデータを収集し学習する場合に有効です。また、複数の組織が協力して学習を行う場合にも利用されることがあります。ただし、データの分散性やプライバシー保護など、いくつかの課題が存在します。
クラウド移行 Cloud Migration
一般的に言えば、データ、ワークロード、IT リソース、アプリケーションなどのデジタル資産を、オンデマンドのセルフサービス環境に構築されたクラウド インフラストラクチャに移動する手順について説明します。不確実性を最小限に抑えながら、効率とリアルタイムのパフォーマンスが目標です。
クラウド移行(Cloud Migration)とは、オンプレミス(自社のサーバー)で稼働しているアプリケーションやデータをクラウド上のサービスに移行することを指します。クラウド移行は、コスト削減、スケーラビリティの向上、セキュリティの向上、ビジネスのアジリティーの向上などのメリットがあるため、多くの企業が導入を検討しています。
クラウド移行の導入ポイントとしては、以下のようなものが挙げられます。
- 移行対象の評価:クラウド移行を実施する前に、移行対象のアプリケーションやデータを評価することが必要です。移行に向いているかどうか、移行時に問題が起きる可能性があるかどうか、移行に必要なリソースや時間、コストなどを評価することが大切です。
- 移行の計画:移行の計画を立てることが必要です。移行のスケジュール、移行時の作業内容、移行後のテストや監視などを計画し、移行の全体像を明確にすることが重要です。
- 移行方法の選択:移行方法を選択することが必要です。大きく分けて、リフトアンドシフト、リファクタリング、リプラットフォーミング、リプレースメントの4つの方法があります。それぞれのメリットやデメリットを評価し、最適な方法を選択することが大切です。
- セキュリティの確保:クラウド移行に伴い、セキュリティのリスクが増す可能性があります。セキュリティの確保は、クラウド移行の導入ポイントとして重要な要素の1つです。セキュリティの確保には、クラウドプロバイダーのセキュリティ対策や、アクセス制御、暗号化、監視などの対策が必要です
- パフォーマンスの最適化:クラウド移行後にパフォーマンスが低下してしまうことがあります。パフォーマンスの最適化には、クラウド環境に合わせたアーキテクチャの見直しや、最適なリソースの選択、ネットワークの最適化することが大切です。
以下は、クラウド移行を導入する際のポイントです。
- 移行戦略の明確化:クラウド移行の目的と、移行に伴うコストやリスクに対する見積もりを行い、移行戦略を明確化する必要があります。また、移行後のシステム運用やメンテナンスの負担を軽減するため、適切なクラウドサービスを選択することも重要です。
- セキュリティの確保:クラウドサービスを利用する場合、データセキュリティの確保が重要です。クラウドサービスプロバイダーとの契約書の明確化、データの暗号化、アクセス制御など、セキュリティに関する対策を講じる必要があります。
- テストと評価:クラウド移行前にテストを行い、システムの動作確認を行うことで、問題の早期発見や対策を行うことができます。また、移行後にも定期的に評価を行い、システムの運用改善につなげることが重要です。
- コストの最適化:クラウドサービスを利用する場合、コストの最適化が必要です。サービスの利用料金、リソースの最適化、自動スケーリングの導入など、コスト削減につながる施策を講じることが必要です。
- スキルの獲得:クラウド移行には、クラウドサービスの知識や技術が必要です。スタッフのスキルアップや、外部の専門家の導入など、スキルの獲得に取り組むことが重要です。
- マイグレーションの計画:クラウド移行は、システム全体の移行に加え、データやアプリケーションの移行など、多くのタスクが必要です。これらを計画的に実行し、マイグレーションの期間中に適切なバックアップを行うことが必要です。
これらのポイントを踏まえ、クラウド移行を計画することで、より効率的かつ安全なシステム運用が可能となります。
2023における Web3 とメタバースの違い
Web3とMetaverse は、ビジネスと金融の世界で話題と熱意を生み出している 2 つの強力なフレーズまたは概念です。大多数の人は、世界が Web2 から Web3 に移行したことをまだ知らず、これらの言葉がしばしば混同されています。それらはいくつかの方法でリンクされていますが、異なる概念を反映しています。
世界が次世代のインターネット ユーザーに移行するにつれて、この 2 つの言葉の違いを理解する必要があります。その前に、web3 とメタバースを定義して、これら 2 つの概念をよりよく理解しましょう。
Web3とは?
Web3 は、制御されたプラットフォームではなく、分散型自律組織 (DAO) やブロックチェーンなどの分散技術に基づいて構築された分散型インターネットに関連しています。ユーザーは、アプリが操作され、データが保存されるシステム、サーバー、およびネットワークを所有します。
メタバースとは?
メタバースとして知られる宇宙は、シミュレートされた環境です。はい、それは「サイバースペース」という名前に取って代わった単なる派手なフレーズです。この用語自体は、特定の種類のテクノロジではなく、人々がテクノロジとやり取りする方法の広範な (そしてしばしば投機的な) 変化を暗示しています。前述の技術が普及するにつれて、言葉自体が時代遅れになる可能性があります。
Web3 とメタバースはどのように接続しますか
メタバースと Web 3.0 は同じものではありませんが、将来のインターネットに対する完全に反対の見方でもあります。いずれかが発生するか、両方が発生するか、またはどちらも発生しない可能性があり、将来的に合併が発生する可能性があります。
たとえば、デジタル アーティストは、キャラクターがメタバースで着用する衣装を作成し、NFT と一緒に入札でそれを提供する場合があります。これにより、購入者は衣装を完全に所有できるようになります。他の人がそれをコピーした場合、彼らのアバターは模造品に身を包みます. また、VR ヘッドセットではなく、コンピューターやスマートフォンから Web 3.0 にアクセスする可能性もあります。
Web 3.0 と Metaverse の包括的な比較:
Web3 と Metaverse は 2 つの革新的なプラットフォームです。Web3 は、インターネットの 3 番目のイテレーションです。それまでの間、メタバースは、分散型ブロックチェーン ネットワークを利用したシミュレートされた宇宙です。
Web3 と Metaverse
どちらも分散プラットフォームです。Web3 は、ブロックチェーン技術を利用してオープン ネットワークを作成します。これは、Web3 が集中型サーバーではなく、デバイスのピアツーピア ネットワークに基づいていることを意味します。
Web3 を担当する中央集権的な機関はありません。メタバースは、分散型ブロックチェーン技術ネットワーク上で動作するシミュレートされた宇宙です。これにより、より包括的でユーザー主導のエクスペリエンスが可能になります。
ユーザーは、Web3 と Metaverse を使用してデジタル プロパティを所有および管理できます。Web3 は、コインやその他のデジタル商品を受け入れます。これらの資産は分散ウォレットに保管され、完全にユーザーの権限下に置かれます。ユーザーは、メタバースの他のデジタル プロパティと共に、シミュレートされた不動産を所有することもできます。代替不可能なコインはその中にあります。(NFT)。これらの商品は、サイトでも取引および使用できます。
相互運用性は、Web3 と Metaverse が共有するもう 1 つの特徴です。Web3 は、他のブロックチェーン システムと連携することを目的としています。これにより、デジタル資産の交換と、多数のネットワークにわたる分散型アプリ (dApps) の開発と展開が可能になります。同様に、Metaverse は、複数のプラットフォームやネットワークで使用できる自律型アプリや仮想体験を開発するためのフレームワークとして機能することを目的としています。
Web 3.0 とメタバースはどちらも、消費者に没入型の出会いを提供します。メタバースは、仮想現実と拡張現実を利用して、よりダイナミックで興味深いユーザー エクスペリエンスを提供します。一方、Web3 は、よりスムーズで使いやすいエクスペリエンスを提供することを目指しています。従来の Web アプリケーションよりも安全で、効果的で、透明性の高い分散型アプリケーションが使用されます。
Web3 と Metaverse は、コミュニティによって制御されるプラットフォームです。分散型 Web を作成して維持するために、Web3 は開発者、ユーザー、およびその他のパートナーの積極的な関与に依存しています。同様に、Metaverse のコミュニティは、仮想体験とアプリの作成、プラットフォームの管理、および将来のパスに関する選択を担当しています。
 殿堂入り記事
殿堂入り記事
発送代行完全ガイド
発送代行に関しての基礎知識が全てわかる徹底ガイドです。発送代行サービスを検討されているEC事業者様は是非ご覧下さい。
物流企業
株式会社富士ロジテックホールディングス
通販・D2C・Eコマース事業者の
EC物流代行・発送代行・オムニチャネルコマースでの流通加工から店舗物流までを、一般社団法人 通販エキスパート協会認定スペシャリスト:「通販CXマネジメント」・「フルフィルメントCX」メンバーとスタッフがサポート致します。
全国11拠点のDC/FCから、先進RaaSマテハンロボット・RFIDなどと、OMS・WMSとコマースシステムをAPIで連携して、物流・発送代行サービスを「スタートアップ特別限定プラン」から、100億円を超える事業者に最適な分散保管・分散出荷、返品・交換サービスまでを一貫でデザインする「顧客購買後体験」によって、LTVの向上が実現できる「感動物流サービス」を提供中です。物流業界の最新トレンドを盛り込んだお役立ち資料も無料でご提供しています。
あなたはこちらのコラムにもご興味がおありかもしれません おすすめコラム

スキンケアブランドのためのブログコンテンツ

【オンラインセミナー】こじみくさんが語る!普通のOLが総フォロワー3.5万人、ブランドのファンを作るSNS運営ぶっちゃけトーク お知らせ スキンケアブランド ソーシャルメディアマーケティング

ビューティーブランド コミュニティトレンド

スキンケアブランドのためのコンテンツマーケティングガイド

在庫評価方法 ユニファイドコマースとオムニチャネル とは

化粧品ビジネスのためのユニークなセールスポイント(USP)を見つけるポイント

最適化された在庫管理 オムニチャネル小売企業が効率と売上を向上させるため

スキンケアブランドの新成長はデータ駆動型CXへ、パーソナライズとコミュニケーション主体のCRMに変わる
タグ一覧
カテゴリー

物流のノウハウがつまったお役立ち資料
通販・EC物流業界で長年にわたって培ったCXなどで成功するノウハウをまとめた資料を無料でダウンロードいただけます。

HATME、独自のノウハウを活かして万全な体制で御社のECを支援します。
①対話重視のコンサルティングでECサイトの立ち上げと成長を支援
②100%正社員のプロジェクトチームで御社に最適な支援サービスを提供
③EC業界で10年以上、400社以上の運用実績による独自ノウハウを活用

購入後体験を配送情報からデザインする
購入後体験を顧客視点で提供すると
①人々がブランドサイトに戻ってくるよう導けます。②再注文の基礎を築きAOV/CLVをアップさせます。③商品とCSへの満足を保証できます。④顧客フィードバックを収集とSNSポストして、コミュニケーションができます。⑤顧客エクスペリエンスを創造してエンゲージできます。

発送代行とは?発送代行の業務内容とサービスの種類
EC:eコマース事業者、オムニチャネル小売事業に商品の発送代行の需要が高まっている理由や、発送代行サービスの対応範囲返品・交換、購買後体験、流通加工、などのポイント解説。

化粧品通販に最適な物流代行サービスの対応機能
化粧品(コスメ・ビューティー)物流におけるEC:eコマースと、サブスクリプションにおける購入(購買)体験のポイントや、アウトソーシングのメリット、CXを通じての売上げアップのポイントなどを解説。
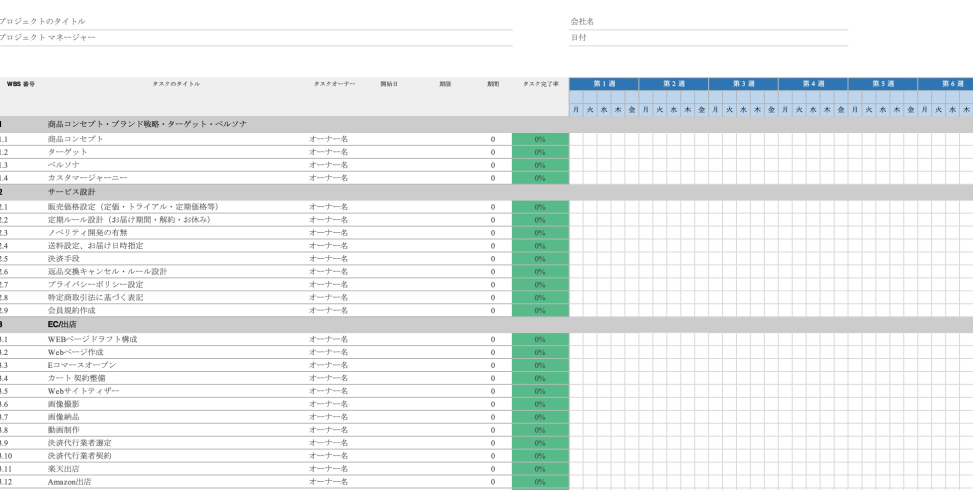
EC立ち上げ!必須TODOリスト
EC:eコマースビジネスを立ち上げる際に、検討するべき項目、コマースシステムとMAなどとの連携、CXとCRM、サブスクリプション、トランザクションメール、フルフィルメント、などのチェックポイントをEXCELシートにまとめました。シートはそのまま活用できます。

スタートアップ新規事業者様限定プランのご紹介
ShopifyとShopify Plusなどのコマースプラットフォームを活用している、DTC/D2C 3.0のブランドのグロースハックをサポートするための、物流サービスを提供する特別限定料金プランの概要をご紹介します。
![[Yahooストアと楽天市場のEC担当者向け]ラベル取得に向けた物流攻略ガイド](https://cdn.shopify.com/s/files/1/0558/8323/5489/files/w_paper01.png?v=1738665471)
[Yahooストアと楽天市場のEC担当者向け]ラベル取得に向けた物流攻略ガイド
本書では、商品が優良配送と最強翌日配送に求められる条件を解説し、物流を外注する際に制約を受けやすい条件をチェックリスト形式にまとめたうえで解決方法を提示します。